Flume入门
介绍
背景
Flume
官网: Flume User Guide 日常使用
架构一:
access.log ==> Flume ==> HDFS ==> 离线处理
access.log ==> Flume ==> Kafka ==> 实时处理
架构二:
==> HDFS
access.log ==> Flume ==> Kafka
==> 流处理
ELK
ES
Logstash
Kibana
Beats
ng:
og: 0.9
https://github.com/cloudera/
https://github.com/cloudera/flume-ng
github.com/apache/flume
mvn clean package -DskipTests 编译命令
Flume三个核心组件
Source : 对接数据源 A
avro **** 序列化框架
exec 监听文件
Spooling Directory 监听文件夹
Taildir Source ***** 断点续传
kafka
netcat 监听端口
http
Custom
Channel: 聚集 解耦
1 2 3 4 5 Source和Sink之间的一个缓冲区 memory file kafka jdbc
Sink : 对接目的地 B
1 2 3 4 5 hdfs logger 测试 avro kafka * Custom
配置文件
阅读官网使用说明即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # example.conf: A single-node Flume configuration a1: Agent的名字 需求:监听localhost机器的44444端口,接收到数据sink到终端 # Name the components on this agent 配置各种名字 a1.sources = r1 配置source的名字 a1.sinks = k1 配置sink的名字 a1.channels = c1 配置channel的名字 # Describe/configure the source 配置source的基本属性 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Use a channel which buffers events in memory 配置channel的基本属性 a1.channels.c1.type = memory # Describe the sink 配置sink的基本属性 a1.sinks.k1.type = logger # Bind the source and sink to the channel 连线 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
安装部署
上传tar.gz包 解压 配置环境变量
1 2 3 4 5 6 7 [bigdata@hadoop001 software]$ tar -xzvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C ~/app/ [bigdata@hadoop001 app]$ ln -s apache-flume-1.6.0-cdh5.16.2-bin/ flume [root@hadoop001 ~]# vi /etc/profile export FLUME_HOME=/home/bigdata/app/flume export PATH=${FLUME_HOME}/bin:$PATH
目录结构
$FLUME_HOME/bin/ 常用命令 如: flume-ng
$FLUME_HOME/conf 配置文件, 根据模板 copy一份修改
1 2 3 [bigdata@hadoop001 conf]$ cp flume-env.sh.template flume-env.sh [bigdata@hadoop001 conf]$ vi flume-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_181
简单使用
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [bigdata@hadoop001 flume]$ mkdir config [bigdata@hadoop001 config]$ vi example.conf a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
运行命令
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/example.conf \ -Dflume.root.logger=INFO,console
a1==>agent的名字
conf==>flume的conf文件夹
conf-file==>自己写的配置文件
-D设置java环境变量的一些K,V
【报错】
1 2 3 [bigdata@hadoop001 config]$ telnet localhost 44444 Trying 127.0.0.1... telnet: connect to address 127.0.0.1: Connection refused
检查nc命令是否可用
1 2 [bigdata@hadoop001 config]$ nc -kl 127.0.0.1 444444 -bash: nc: command not found
不可用,下载nc
1 [root@hadoop001 ~]# yum install nc -y
重新运行flume-ng命令,telnet端口,输入一些值,查看flume终端的变化
1 2 3 4 5 6 7 8 9 10 11 12 [bigdata@hadoop001 config]$ telnet localhost 44444 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. 1 OK 2 OK 2021-02-15 15:49:53,641 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] 2021-02-15 15:50:02,639 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 31 0D 1. } 2021-02-15 15:50:03,135 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 32 0D 2. }
telnet输入的字符: 长度只显示16个, 数据未丢
数据传输 单元 Event
{ headers:{} body: 32 0D 2. } 一条数据
使用1: exec hdfs
exec ==> memory ==> hdfs
监听文件的变化
**注意: 文件路径最好使用全路径…**坑
flume-ng agent
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define agent exec-hdfs-agent.sources = exec-source exec-hdfs-agent.channels = exec-memory-channel exec-hdfs-agent.sinks = hdfs-sink #define source exec-hdfs-agent.sources.exec-source.type = exec exec-hdfs-agent.sources.exec-source.command = tail -F ~/data/data.log #define channel exec-hdfs-agent.channels.exec-memory-channel.type = memory #define sink exec-hdfs-agent.sinks.hdfs-sink.type = hdfs exec-hdfs-agent.sinks.hdfs-sink.hdfs.path = hdfs://hadoop001:9000/data2/tail exec-hdfs-agent.sinks.hdfs-sink.hdfs.fileType = DataStream exec-hdfs-agent.sinks.hdfs-sink.hdfs.writeFormat = Text exec-hdfs-agent.sinks.hdfs-sink.hdfs.batchSize = 10 #bind source and sink to channel exec-hdfs-agent.sources.exec-source.channels = exec-memory-channel exec-hdfs-agent.sinks.hdfs-sink.channel = exec-memory-channel
小文件问题: 增加几个参数, 但时效性会变弱
1 2 3 exec-hdfs-agent.sinks.hdfs-sink.hdfs.rollInterval = 50 exec-hdfs-agent.sinks.hdfs-sink.hdfs.rollSize = 1000000 exec-hdfs-agent.sinks.hdfs-sink.hdfs.rollCount = 0
使用2: Spooling Directory
Spooling Directory source
监听文件夹
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/bigdata/data/spool a1.sources.r1.fileHeader = true a1.sources.r1.fileHeaderKey = lxl_header_key # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
flume-ng agent
copy一些文件到目标文件夹
1 [bigdata@hadoop001 data]$ cp emp.txt ~/data/spool
文件名不能重复, 否则会挂掉
使用3: Spooling HDFS
timestamp
1 2 3 4 5 flume-ng agent \ --name spooling-hdfs-agent \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume-spooling-timestamp.conf \ -Dflume.root.logger=INFO,console
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #define agent spooling-hdfs-agent.sources = spooling-source spooling-hdfs-agent.channels = spooling-memory-channel spooling-hdfs-agent.sinks = hdfs-sink #define source spooling-hdfs-agent.sources.spooling-source.type = spooling spooling-hdfs-agent.sources.spooling-source.spoolDir = /home/bigdata/data/logs #define channel spooling-hdfs-agent.channels.spooling-memory-channel.type = memory #define sink spooling-hdfs-agent.sinks.hdfs-sink.type = hdfs spooling-hdfs-agent.sinks.hdfs-sink.hdfs.path = hdfs://hadoop001:9000/data2/logs/%Y%m%d%H%M spooling-hdfs-agent.sinks.hdfs-sink.hdfs.fileType = CompressedStream spooling-hdfs-agent.sinks.hdfs-sink.hdfs.codeC = org.apache.hadoop.io.compress.GzipCodec spooling-hdfs-agent.sinks.hdfs-sink.hdfs.filePrefix = page-views spooling-hdfs-agent.sinks.hdfs-sink.hdfs.rollInterval = 30 spooling-hdfs-agent.sinks.hdfs-sink.hdfs.rollSize = 0 spooling-hdfs-agent.sinks.hdfs-sink.hdfs.rollCount = 1000000 #important four lines configuration spooling-hdfs-agent.sinks.hdfs-sink.hdfs.useLocalTimeStamp = true spooling-hdfs-agent.sinks.hdfs-sink.hdfs.round = true spooling-hdfs-agent.sinks.hdfs-sink.hdfs.roundUnit = minute spooling-hdfs-agent.sinks.hdfs-sink.hdfs.roundValue = 1 #bind source and sink to channel spooling-hdfs-agent.sources.spooling-source.channels = spooling-memory-channel spooling-hdfs-agent.sinks.hdfs-sink.channel = spooling-memory-channel
使用4: tailDir 断点续传
准备需要的目录 mkdir data/flume position
mkdir data/flume/test1 data/flume/test2
cd test1 ==>vi example.log
flume-ng agent
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.positionFile = /home/bigdata/data/position/taildir_position.json a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1 = /home/bigdata/data/flume/test1/example.log a1.sources.r1.headers.f1.headerKey1 = value1 a1.sources.r1.filegroups.f2 = /home/bigdata/data/flume/test2/.*log.* a1.sources.r1.headers.f2.headerKey1 = value2 a1.sources.r1.headers.f2.headerKey2 = value2-2 a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
example.log追加数据
控制台显示:
Event: { headers:{headerKey1=value1, file=/home/bigdata/data/flume/test1/example.log} body: 31 1 }
查看position文件
1 2 3 [bigdata@hadoop001 data]$ tail -200f position/taildir_position.json [{"inode":1583696,"pos":2,"file":"/home/bigdata/data/flume/test1/example.log"}]tail: position/taildir_position.json: file truncated [{"inode":1583696,"pos":2,"file":"/home/bigdata/data/flume/test1/example.log"}]tail: position/taildir_position.json: file truncated
测试断点续传
1 2 3 4 5 6 7 8 [bigdata@hadoop001 ~]$ jps -m 31410 NameNode 31843 Jps -m 31717 Application --name a1 --conf-file /home/bigdata/app/flume/config/taildir-memory-logger.conf 31543 DataNode 31708 SecondaryNameNode [bigdata@hadoop001 ~]$ kill -9 31717
再继续向文件和文件夹中写数据
1 2 3 4 5 [bigdata@hadoop001 test2]$ cp ~/data/login.txt 1.log [bigdata@hadoop001 test2]$ cp ~/data/login.txt 2.log [bigdata@hadoop001 test2]$ cd ../test1 [bigdata@hadoop001 test1]$ echo 3 >> example.log [bigdata@hadoop001 test1]$ echo 4 >> example.log
重启, 数据不丢
1 2 3 4 5 OURCE, name: r1 started 2021-02-15 19:22:22,544 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{headerKey1=value1, file=/home/bigdata/data/flume/test1/example.log} body: 33 3 } 2021-02-15 19:22:22,544 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{headerKey1=value1, file=/home/bigdata/data/flume/test1/example.log} body: 34 4 } 2021-02-15 19:22:22,545 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{headerKey1=value2, headerKey2=value2-2, file=/home/bigdata/data/flume/test2/2.log} body: 70 6B 2C 32 30 32 31 30 38 30 31 pk,20210801 } 2021-02-15 19:22:22,545 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{headerKey1=value2, headerKey2=value2-2, file=/home/bigdata/data/flume/test2/2.log} body: 70 6B 2C 32 30 32 31 30 38 30 32 pk,20210802 }
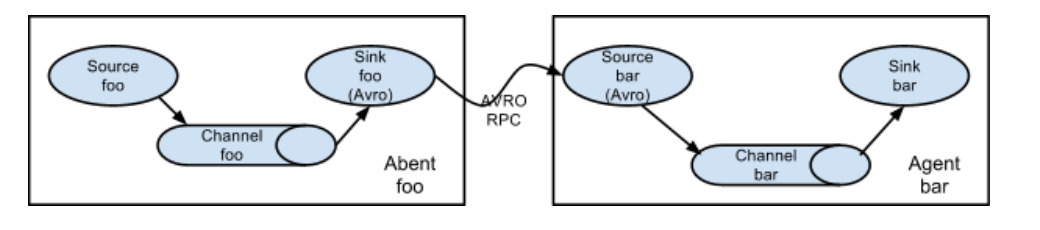
使用5: avroclient
RPC: Remote Procedure Call 远程过程调用
序列化:将某个数据结构变成二进制
启动
1 2 3 4 5 flume-ng agent \ --name avroclient-agent \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume-avroclient.conf \ -Dflume.root.logger=INFO,console
另一个窗口 使用avro-client的命令
1 2 3 4 5 flume-ng avro-client \ --host localhost \ --port 44444 \ --filename /home/bigdata/data/login.txt \ --conf $FLUME_HOME/conf
查看数据是否传输
问题: NettyServer CLOSED ==> 只能使用一次
使用6: multi-agent flow
avro-sink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #define agent avro-sink-agent.sources = exec-source avro-sink-agent.channels = avro-memory-channel avro-sink-agent.sinks = avro-sink #define source avro-sink-agent.sources.exec-source.type = exec avro-sink-agent.sources.exec-source.command = tail -F /home/bigdata/data/avro_access.data #define channel avro-sink-agent.channels.avro-memory-channel.type = memory #define sink avro-sink-agent.sinks.avro-sink.type = avro avro-sink-agent.sinks.avro-sink.hostname = 0.0.0.0 avro-sink-agent.sinks.avro-sink.port = 55555 #bind source and sink to channel avro-sink-agent.sources.exec-source.channels = avro-memory-channel avro-sink-agent.sinks.avro-sink.channel = avro-memory-channel
avro-source
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #define agent avro-source-agent.sources = avro-source avro-source-agent.channels = avro-memory-channel avro-source-agent.sinks = logger-sink #define source avro-source-agent.sources.avro-source.type = avro avro-source-agent.sources.avro-source.bind = 0.0.0.0 avro-source-agent.sources.avro-source.port = 55555 #define channel avro-source-agent.channels.avro-memory-channel.type = memory #define sink avro-source-agent.sinks.logger-sink.type = logger #bind source and sink to channel avro-source-agent.sources.avro-source.channels = avro-memory-channel avro-source-agent.sinks.logger-sink.channel = avro-memory-channel
先启动下游(avro-source-agent)
1 2 3 4 5 flume-ng agent \ --name avro-source-agent \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume-avro-source.conf \ -Dflume.root.logger=INFO,console
再启动下游
1 2 3 4 5 flume-ng agent \ --name avro-sink-agent \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume-avro-sink.conf \ -Dflume.root.logger=INFO,console
数据生成
1 [bigdata@hadoop001 data]$ for i in {1..100};do echo "lxl $i" >> /home/bigdata/data/avro_access.data;sleep 0.1;done
查看source端的控制台, 数据传输成功
1 2 [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6C 78 6C 20 39 39 lxl 99 } [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 6C 78 6C 20 31 30 30 lxl 100 }
channel selector
replicating channel selector
netcat ==>memory(c1) ==>hdfs(sink1)
==>memory(c2) ==>logger(sink2)
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Describe the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the selecotr a1.sources.r1.selector.type = replicating a1.sources.r1.channels = c1 c2 # Describe the sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/data2/tail2/replicating/%Y%m%d%H%M a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.filePrefix = hdfsFlume a1.sinks.k1.hdfs.writeFormat = Text a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.roundValue = 1 a1.sinks.k2.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c2.type = memory # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
运行
flume-ng agent
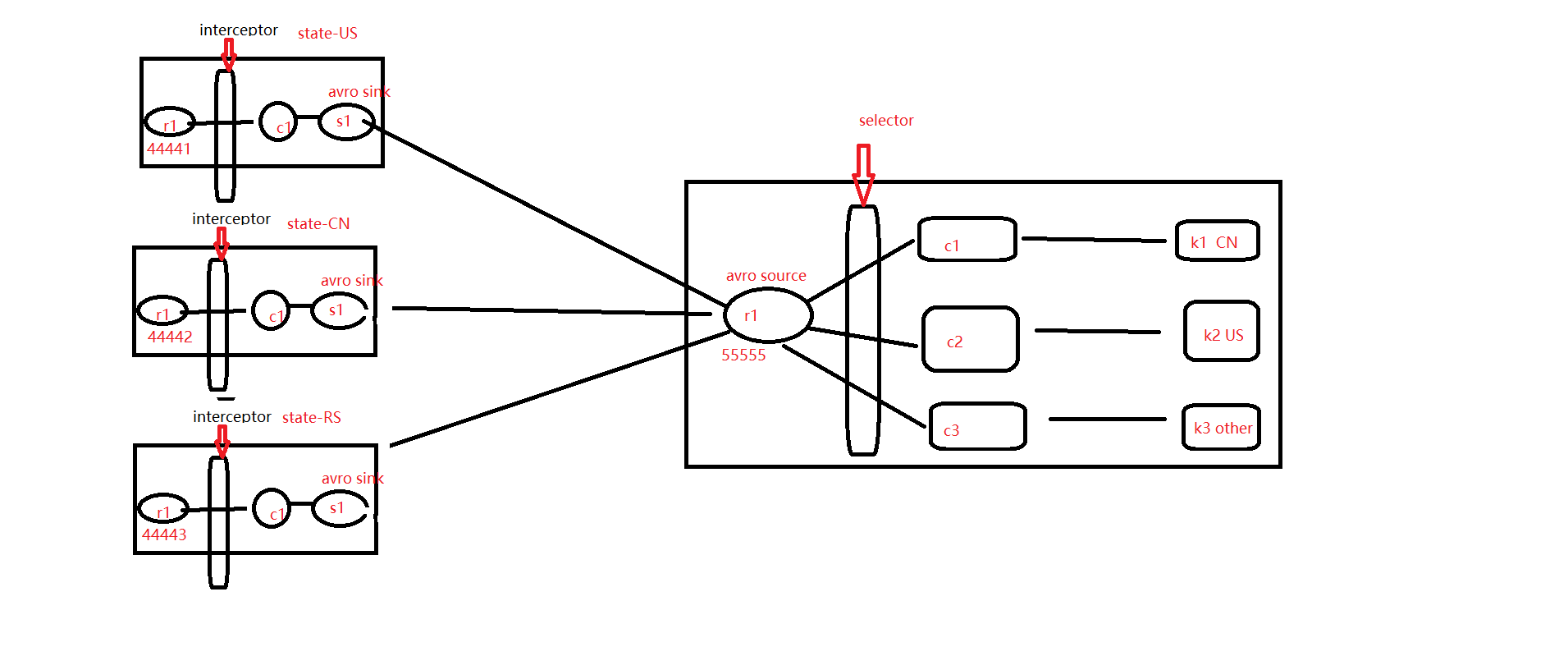
Multiplexing Channel Selector
需求图
配置文件
multi_selector1.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44441 # Describe the interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = state a1.sources.r1.interceptors.i1.value = US # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = 0.0.0.0 a1.sinks.k1.port = 55555 # Use a channel which buffers events in memory a1.channels.c1.type = memory # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
multi_selector2.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe the source a2.sources.r1.type = netcat a2.sources.r1.bind = localhost a2.sources.r1.port = 44442 # Describe the interceptor a2.sources.r1.interceptors = i1 a2.sources.r1.interceptors.i1.type = static a2.sources.r1.interceptors.i1.key = state a2.sources.r1.interceptors.i1.value = CN # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = 0.0.0.0 a2.sinks.k1.port = 55555 # Use a channel which buffers events in memory a2.channels.c1.type = memory # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
multi_selector3.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe the source a3.sources.r1.type = netcat a3.sources.r1.bind = localhost a3.sources.r1.port = 44443 # Describe the interceptor a3.sources.r1.interceptors = i1 a3.sources.r1.interceptors.i1.type = static a3.sources.r1.interceptors.i1.key = state a3.sources.r1.interceptors.i1.value = RS # Describe the sink a3.sinks.k1.type = avro a3.sinks.k1.hostname = 0.0.0.0 a3.sinks.k1.port = 55555 # Use a channel which buffers events in memory a3.channels.c1.type = memory # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c3
multi_selector_collector.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #define agent collector.sources = r1 collector.channels = c1 c2 c3 collector.sinks = k1 k2 k3 #define source collector.sources.r1.type = avro collector.sources.r1.bind = 0.0.0.0 collector.sources.r1.port = 55555 #define selector collector.sources.r1.selector.type = multiplexing collector.sources.r1.selector.header = state collector.sources.r1.selector.mapping.US = c1 collector.sources.r1.selector.mapping.CN = c2 collector.sources.r1.selector.default = c3 #define channel collector.channels.c1.type = memory collector.channels.c2.type = memory collector.channels.c3.type = memory #define sink collector.sinks.k1.type = file_roll collector.sinks.k1.sink.directory = /home/bigdata/tmp/multiplexing/k1 collector.sinks.k2.type = file_roll collector.sinks.k2.sink.directory = /home/bigdata/tmp/multiplexing/k2 collector.sinks.k3.type = logger #bind source and sink to channel collector.sources.r1.channels = c1 c2 c3 collector.sinks.k1.channel = c1 collector.sinks.k2.channel = c2 collector.sinks.k3.channel = c3
启动顺序
1 启动下游
1 2 3 4 5 flume-ng agent \ --name collector \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/multi_selector_collector.conf \ -Dflume.root.logger=INFO,console
启动上游
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/multi_selector1.conf \ -Dflume.root.logger=INFO,console
1 2 3 4 5 flume-ng agent \ --name a2 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/multi_selector2.conf \ -Dflume.root.logger=INFO,console
1 2 3 4 5 flume-ng agent \ --name a3 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/multi_selector3.conf \ -Dflume.root.logger=INFO,console
再启动3个窗口 telnet 配置中的三个端口
写入数据, 查看k1和k2和控制台是否有数据
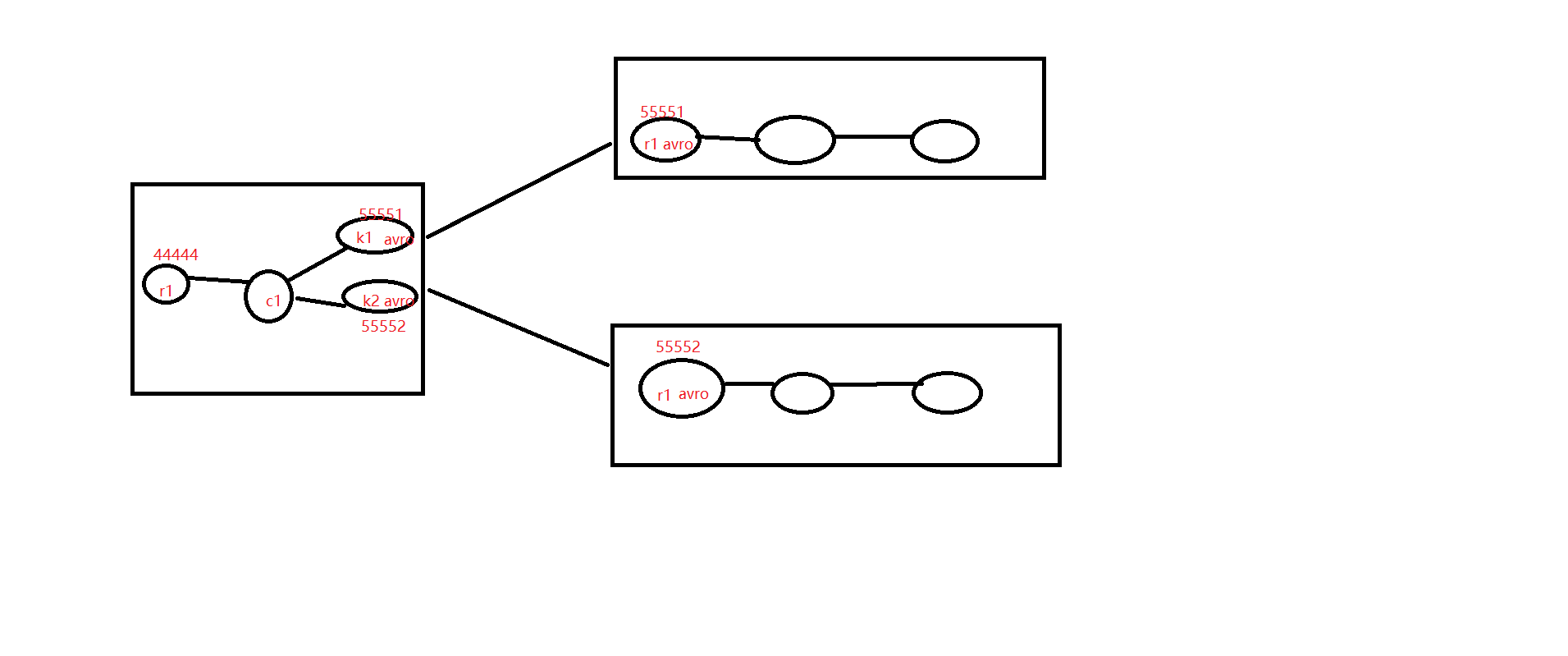
sink Processor
需求图
配置文件
failoversink.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 # define agent: a1 a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2 # define source a1.sources.r1.type = netcat a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 44444 # define sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = 0.0.0.0 a1.sinks.k1.port = 55551 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 0.0.0.0 a1.sinks.k2.port = 55552 # define the sink group a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000 #define channel a1.channels.c1.type = memory # build a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
failovercollector-1.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #define agent collector1.sources = r1 collector1.channels = c1 collector1.sinks = k1 #define source collector1.sources.r1.type = avro collector1.sources.r1.bind = 0.0.0.0 collector1.sources.r1.port = 55551 #define channel collector1.channels.c1.type = memory #define sink collector1.sinks.k1.type = logger #bind source and sink to channel collector1.sources.r1.channels = c1 collector1.sinks.k1.channel = c1
failovercollector-2.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #define agent collector2.sources = r1 collector2.channels = c1 collector2.sinks = k1 #define source collector2.sources.r1.type = avro collector2.sources.r1.bind = 0.0.0.0 collector2.sources.r1.port = 55552 #define channel collector2.channels.c1.type = memory #define sink collector2.sinks.k1.type = logger #bind source and sink to channel collector2.sources.r1.channels = c1 collector2.sinks.k1.channel = c1
启动顺序
先启动下游 collector
1 2 3 4 5 flume-ng agent \ --name collector1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/failovercollector-1.conf \ -Dflume.root.logger=INFO,console
1 2 3 4 5 flume-ng agent \ --name collector2 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/failovercollector-2.conf \ -Dflume.root.logger=INFO,console
再启动上游 sink
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/failoversink.conf \ -Dflume.root.logger=INFO,console
Telnet 44444 输入数据
1 2 3 4 5 6 7 8 [bigdata@hadoop001 config]$ telnet localhost 44444 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. A OK B OK
collector2输出数据===> 数据越大 优先级越高
failover测试
杀死2的进程 1中输出
过了10秒 再启动2 2中输出
1 2 3 4 5 flume-ng agent \ --name collector2 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/failovercollector-2.conf \ -Dflume.root.logger=INFO,console
interceptor
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 # define agent: a1 a1.sources = r1 a1.channels = c1 a1.sinks = k1 # define source a1.sources.r1.type = netcat a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 44444 a1.sources.r1.interceptors = i1 i2 i3 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = a a1.sources.r1.interceptors.i1.value = aa a1.sources.r1.interceptors.i1.key = b a1.sources.r1.interceptors.i1.value = bb a1.sources.r1.interceptors.i2.type = host a1.sources.r1.interceptors.i2.useIP = false a1.sources.r1.interceptors.i2.hostHeader = hostname a1.sources.r1.interceptors.i3.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder a1.sources.r1.interceptors.i3.headerName = uuid #define channel a1.channels.c1.type = memory # define sink a1.sinks.k1.type = logger # build a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/other-interceptor.conf \ -Dflume.root.logger=INFO,console
telnet localhost 44444
输入数据
查看终端的输出
1 2 3 [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{b=bb, hostname=hadoop001, uuid=77e286ed-0240-485a-82d5-6f3f5bfc0afb} body: 31 0D 1. } [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{b=bb, hostname=hadoop001, uuid=18ee961e-6150-4fcd-8cec-008f2a4370d8} body: 32 0D 2. } [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{b=bb, hostname=hadoop001, uuid=317aceb9-2b87-4719-80eb-b0ae15ac275b} body: 33 0D 3. }
static拦截器
如果配置了多个, 后面覆盖前面的, 保留最后一个 key value
code整合
加入依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 <flume.version>1.6.0-cdh5.16.2</flume.version> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-node</artifactId> <version>${flume.version}</version> </dependency> <dependency> <groupId>org.apache.flume.flume-ng-clients</groupId> <artifactId>flume-ng-log4jappender</artifactId> <version>${flume.version}</version> </dependency>
resources中加入配置文件log4j.properties
1 2 3 4 5 6 7 8 9 10 11 log4j.rootLogger=INFO,stdout,myflume log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = %d{HH:mm:ss,SSS}[%t] [%c] [%p] - %m%n log4j.appender.myflume = org.apache.flume.clients.log4jappender.Log4jAppender log4j.appender.myflume.Hostname = hadoop001 log4j.appender.myflume.Port = 44444 log4j.appender.myflume.UnsafeMode = true
config目录中的配置文件flume-code.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 agent1.sources = avro-source agent1.channels = logger-channel agent1.sinks = log-sink # define channel agent1.channels.logger-channel.type = memory # define source agent1.sources.avro-source.channels = logger-channel agent1.sources.avro-source.type = avro agent1.sources.avro-source.bind = 0.0.0.0 agent1.sources.avro-source.port = 44444 # define sink agent1.sinks.log-sink.channel = logger-channel agent1.sinks.log-sink.type = logger
启动
flume-ng agent
自定义source&sink&interceptor
依赖
1 2 3 4 5 6 <dependencies> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> </dependency> </dependencies>
服务器上创建目录
1 2 3 [bigdata@hadoop001 flume]$ mkdir plugins.d [bigdata@hadoop001 plugins.d]$ mkdir -p lxl-source/lib [bigdata@hadoop001 plugins.d]$ mkdir -p lxl-sink/lib
自定义source
code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 /** * 自定义Source * 为Event 添加一个前缀和后缀 */ public class RuozedataSource extends AbstractSource implements Configurable, PollableSource { String prefix; String suffix; /** * 操作event * @return * @throws EventDeliveryException */ @Override public Status process() throws EventDeliveryException { Status status = null; try { // This try clause includes whatever Channel/Event operations you want to do // Receive new data for(int i =0;i<5;i++){ SimpleEvent event = new SimpleEvent(); event.setBody((prefix+"-"+i+"-"+suffix).getBytes()); // Store the Event into this Source's associated Channel(s) getChannelProcessor().processEvent(event); status = Status.READY; } } catch (Exception e) { // Log exception, handle individual exceptions as needed status = Status.BACKOFF; e.printStackTrace(); } try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } return status; } @Override public long getBackOffSleepIncrement() { return 0; } @Override public long getMaxBackOffSleepInterval() { return 0; } /** * 封装参数信息 * @param context */ @Override public void configure(Context context) { prefix =context.getString("prefix","bigdata"); suffix = context.getString("suffix"); } }
配置文件
cd config
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source # 自定义的source类名 a1.sources.r1.type = lxl.bigdata.flume.RuozedataSource a1.sources.r1.prefix = lxl_source_prefix a1.sources.r1.suffix = lxl_source_suffix # Use a channel which buffers events in memory a1.channels.c1.type = memory # Describe the sink a1.sinks.k1.type = logger # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
运行
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/lxl_source.conf \ -Dflume.root.logger=INFO,console
自定义sink
code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public class RuozedataSink extends AbstractSink implements Configurable { private final static Logger log = LoggerFactory.getLogger("RuozedataSink"); String prefix; String suffix; /** * 操作event * @return * @throws EventDeliveryException */ @Override public Status process() throws EventDeliveryException { Status status = null; // Start transaction Channel ch = getChannel(); Transaction txn = ch.getTransaction(); txn.begin(); try { Event event; // This try clause includes whatever Channel operations you want to do while (true){ event= ch.take(); if(null!=event){ break; } } String body = new String(event.getBody()); log.info(prefix+"_"+body+"_"+suffix); txn.commit(); status = Status.READY; } catch (Exception e) { txn.rollback(); status = Status.BACKOFF; log.error(e.getMessage()); }finally { txn.close(); } return status; } /** * 封装参数信息 * @param context */ @Override public void configure(Context context) { prefix =context.getString("prefix","Ruozedata_sink"); suffix = context.getString("suffix"); } }
配置文件
lxl_sink.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 44444 # Use a channel which buffers events in memory a1.channels.c1.type = memory # Describe the sink # 自定义的source类名 a1.sinks.k1.type = lxl.bigdata.flume.RuozedataSink a1.sinks.k1.prefix = lxl_s_pre a1.sinks.k1.suffix = lxl_s_suf # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
运行
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/lxl_sink.conf \ -Dflume.root.logger=INFO,console
1 2 3 另一个窗口 telnet localhost 4444 输入数据查看前后缀
自定义interceptor
1 [bigdata@hadoop001 plugins.d]$ mkdir -p lxl-interceptor/lib
code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class RuozedataInterceptor implements Interceptor { List<Event> events; @Override public void initialize() { events = new ArrayList<>(); } @Override public Event intercept(Event event) { final Map<String, String> headers = event.getHeaders(); final String body = new String(event.getBody()); if(body.contains("ruozedata")){ headers.put("type", "ruozedata"); }else{ headers.put("type","other"); } return event; } @Override public List<Event> intercept(List<Event> List) { events.clear(); for(Event event:List){ events.add(intercept(event)); } return events; } @Override public void close() { } public static class Builder implements Interceptor.Builder{ @Override public Interceptor build() { return new RuozedataInterceptor(); } @Override public void configure(Context context) { } } }
配置文件
flume01 ==>interceptor ==>ruozedata==>flume02
==>other==>flume03
flume01.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Describe the source a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop001 a1.sources.r1.port = 44444 # Describe the interceptor # 自定义的interceptor 注意$Builder a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = lxl.bigdata.flume.RuozedataInterceptor$Builder # Describe the selecotr a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = type a1.sources.r1.selector.mapping.ruozedata = c1 a1.sources.r1.selector.mapping.other = c2 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop001 a1.sinks.k1.port = 44445 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop001 a1.sinks.k2.port = 44446 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c2.type = memory # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
flume02.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 a2.sources = r1 a2.sinks = k1 a2.channels = c1 a2.sources.r1.type = avro a2.sources.r1.bind = hadoop001 a2.sources.r1.port = 44445 a2.channels.c1.type = memory a2.sinks.k1.type = logger a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
flume03.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 a3.sources = r1 a3.sinks = k1 a3.channels = c1 a3.sources.r1.type = avro a3.sources.r1.bind = hadoop001 a3.sources.r1.port = 44446 a3.channels.c1.type = memory a3.sinks.k1.type = logger a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
运行 先启动a2 a3 再启动a1
1 2 3 4 5 flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume01.conf \ -Dflume.root.logger=INFO,console
1 2 3 4 5 flume-ng agent \ --name a2 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume02.conf \ -Dflume.root.logger=INFO,console
1 2 3 4 5 flume-ng agent \ --name a3 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume03.conf \ -Dflume.root.logger=INFO,console