hadoop(三)
HDFS主从架构
namenode :nn 名称节点
-
文件的名称
-
文件的目录结构
-
文件的属性 权限 副本数 创建时间
1
2
3
4
5
6
7
8
9
10
11
12
13[bigdata@hadoop001 ~]$ hdfs dfs -ls /
20/11/25 21:16:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
drwx------ - hadoop supergroup 0 2020-11-22 19:52 /tmp
drwxr-xr-x - hadoop supergroup 0 2020-11-21 21:50 /user
drwxr-xr-x - hadoop supergroup 0 2020-11-22 19:52 /wordcount
[bigdata@hadoop001 ~]$ -
一个文件被对应切割哪些数据块(包含副本数的块) ==》 对应分布在哪些datanode
blockmap 块映射 nn是不会持久化存储这种映射关系
是通过集群的启动和运行时,dn定期汇报blockreport给nn,然后在内存中动态维护这种映射关系。
作用:
管理文件系统的命名空间,其实就是维护文件系统树的文件和文件夹
镜像文件 fsimage
编辑日志文件 editlogs
1 | -rw-rw-r-- 1 hadoop hadoop 42 Nov 25 19:04 edits_0000000000000000511-0000000000000000512 |
secondary namenode: snn 第二名称节点
-
fsimage editlog文件拿过来合并 备份 推送给nn
1
2
3
4
5
6
7
8-rw-rw-r-- 1 hadoop hadoop 42 Nov 25 19:04 edits_0000000000000000511-0000000000000000512
-rw-rw-r-- 1 hadoop hadoop 42 Nov 25 20:04 edits_0000000000000000513-0000000000000000514
-rw-rw-r-- 1 hadoop hadoop 42 Nov 25 21:04 edits_0000000000000000515-0000000000000000516
-rw-rw-r-- 1 hadoop hadoop 4230 Nov 25 20:04 fsimage_0000000000000000514
-rw-rw-r-- 1 hadoop hadoop 62 Nov 25 20:04 fsimage_0000000000000000514.md5
-rw-rw-r-- 1 hadoop hadoop 4230 Nov 25 21:04 fsimage_0000000000000000516
-rw-rw-r-- 1 hadoop hadoop 62 Nov 25 21:04 fsimage_0000000000000000516.md5
-rw-rw-r-- 1 hadoop hadoop 200 Nov 25 21:04 VERSION
将老大的
fsimage_0000000000000000514
edits_0000000000000000515-0000000000000000516 ==》检测点动作 checkpoint
合并 fsimage_0000000000000000516 将516推送给nn
而新的读写记录则在 edits_inprogress_0000000000000000517编辑日志里
dfs.namenode.checkpoint.period 3600
dfs.namenode.checkpoint.txns 1000000
早期为了解决nn是单点的,单点故障,增加一个snn,1小时的checkpoint
虽然能够减轻单点故障的带来的数据丢失风险,但是生产上不允许使用snn
11:00 checkpoint
11:30 数据一直在写 突然nn硬盘挂了 无法恢复
拿snn节点的最新的fsimage,那么只能恢复11点的数据
在生产上是不允许snn,是使用HA 高可靠,是通过配置另外一个实时的备份nn节点,
随时等待老大active nn 挂掉,然后成为老大
datanode: 数据节点 dn
- 存储数据块 和 数据块的校验
[bigdata@hadoop001 subdir0]$ pwd
/home/hadoop/tmp/dfs/data/current/BP-1245831-192.168.0.3-1605965291938/current/finalized/subdir0/subdir0
[bigdata@hadoop001 subdir0]$
- 每隔一定的时间去发送blockreport
dfs.blockreport.intervalMsec 21600000=6h
dfs.datanode.directoryscan.interval 21600=6h
补充:https://ruozedata.github.io/2019/06/06/生产HDFS Block损坏恢复最佳实践(含思考题)/
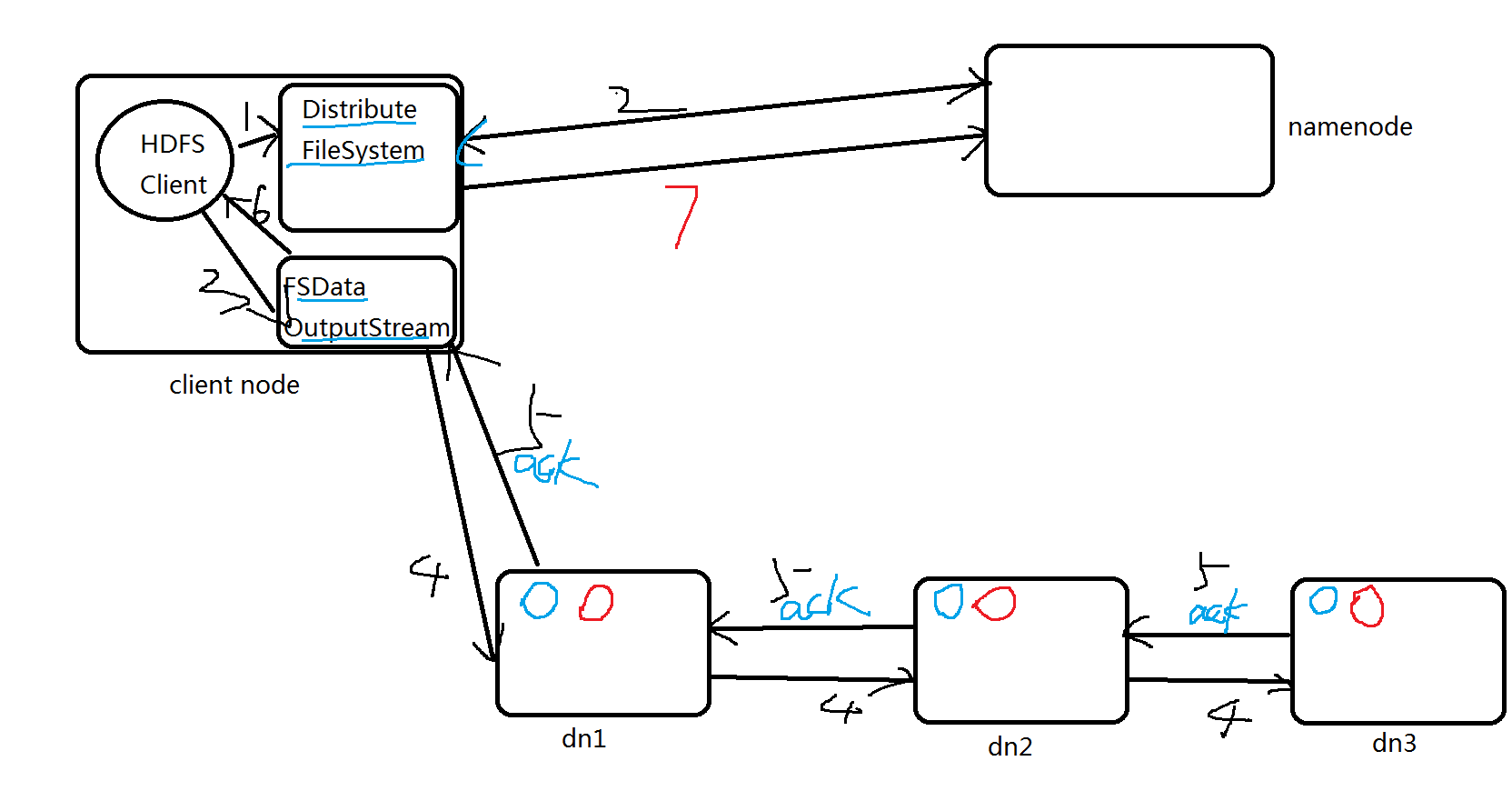
HDFS写流程
对用户是无感知的
-
HDFS Client调用FileSystem.create(filePath)方法,去和NN进行【RPC】通信。
NN会去check这个文件是否存在,是否有权限创建这个文件。
假如都可以,就创建一个新的文件,但是这时没有数据,是不关联任何block的。
NN根据文件的大小,根据块大小 副本数,计算要上传多少的块和对应哪些DN节点上。
最终这个信息返回给客户端【FSDataOutputStream】对象 -
Client 调用客户端【FSDataOutputStream】对象的write方法,
根据【副本放置策略】,将第一个块的第一个副本写到DN1,写完复制到DN2,写完再复制到DN3.
当第三个副本写完,就返回一个ack package确认包给DN2,DN2接收到ack 加上自己写完,
发送ack给DN1,DN1接收到ack加上自己写完,就发送ack给客户端【FSDataOutputStream】对象,
告诉它第一个块三副本写完了。
以此类推。 -
当所有的块全部写完,Client调用【FSDataOutputStream】对象的close方法,
关闭输出流。再次调用FileSystem.complete方法 ,告诉nn文件写成功。
伪分布式 1台dn,副本数参数必须设置是1吗?
设置2 也可以写,显示丢失一个副本
生产上分布式 3台dn,副本数参数是3,如果其中一个dn挂了,数据是否能够写入?
可以的
生产上分布式 >3台dn,副本数参数是3,如果其中一个dn挂了,数据是否能够写入?
肯定写
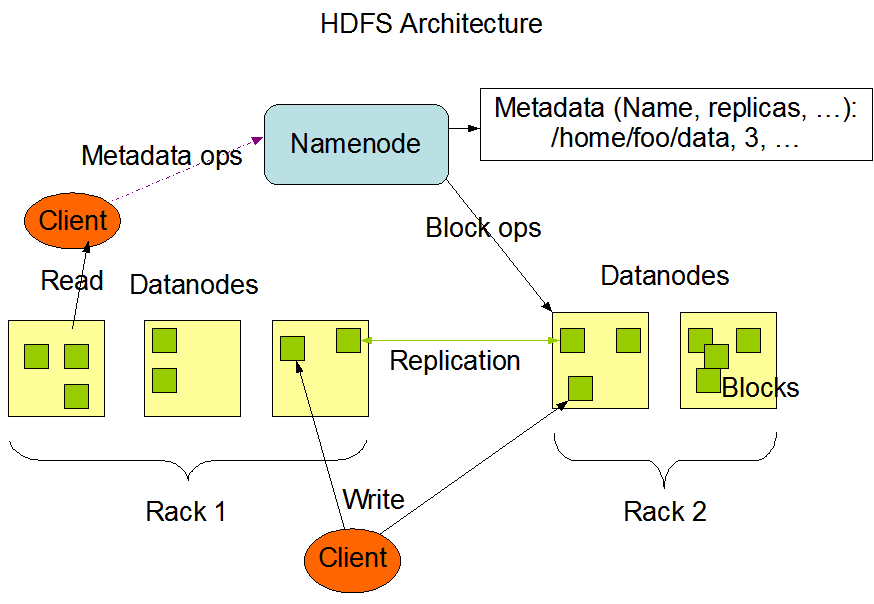
HDFS读流程
-
Client调用FileSystem的open(filePath),
与NN进行【rpc】通信,返回该文件的部分或者全部的block列表
也就是返回【FSDataIntputStream】对象 -
Client调度【FSDataIntputStream】对象的read方法,
与第一个块的最近的DN的进行读取,读取完成后,会check,假如ok就关闭与DN通信。
假如不ok,就会记录块+DN的信息,下次就不从这个节点读取。那么从第二个节点读取。然后与第二个块的最近的DN的进行读取,以此类推。
假如当block的列表全部读取完成,文件还没结束,就调用FileSystem从NN获取下一批次的block列表。 -
Client调用【FSDataIntputStream】对象的close方法,关闭输入流。
副本放置策略
https://www.bilibili.com/video/BV1eE411p7un
生产上读写操作 尽量选择DN节点操作
第一个副本:
放置在上传的DN节点上,就近原则,节省IO
假如非DN节点,就随机挑选一个磁盘不太慢,cpu不太忙的节点。
第二个副本:
放置在第一个副本的不同机架上的某个节点
第三个副本:
与第二个副本放置同一个机架的不同节点上。
如果副本数设置更多,随机放。