hadoop参数调优
container 容器
关于yarn的调优,其实就是调整container
虚拟化 是memory + cpu vcore组成的 是专门运行任务
生产上应该如何调优container参数?
假设128G 16 物理core
1.1 系统装完 消耗 (1G)
1.2 系统要预留20%内存 (1G)
给当前进程服务,防止出现oom-kill机制
Linux系统防止夯住
给未来部署软件预留空间
128*20%=25.6G==26G
还剩:102G
1.3 DN 和 NM 节点
存储和计算一体,数据本地化。
DN = 2G
NM = 4G NM进程本身的内存
102-2-4=96G 是真正container容器总内存 ,这才是真正计算的小弟
1.4 container内存
http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.16.2/
yarn.nodemanager.resource.memory-mb 96G
yarn.scheduler.minimum-allocation-mb 1G 极限情况 96个container容器 内存1G
yarn.scheduler.maximum-allocation-mb 96G 极限情况 1个container容器 内存96G
container容器会不断的自动增加内存1G,cdh有这个参数 默认不动
1.5 container 虚拟core
这个概念是yarn自己引入的,
设计初衷是考虑不同服务器的cpu性能不一样,每个cpu计算能力不一样。
比如某个物理cpu是另外一个物理cpu的2倍,
这时通过设置第一个物理cpu的虚拟core来弥补差异。
虽然是这样说的,后来演变为,大家都是使用虚拟core,
默认值一般都不会去修改,就是2
yarn.nodemanager.resource.pcores-vcores-multiplier 2
yarn.nodemanager.resource.cpu-vcores 32【物理core16*2】
yarn.scheduler.minimum-allocation-vcores 1 极限情况下,是32个
yarn.scheduler.maximum-allocation-vcores 32 极限情况下,是1个
补充:
yarn.nodemanager.pmem-check-enabled true 生产调整
yarn.nodemanager.vmem-check-enabled true 生产调整
yarn.nodemanager.vmem-pmem-ratio 2.1 不动
1.6 生产上如何设置 突破口
yarn.nodemanager.resource.cpu-vcores 32
yarn.scheduler.minimum-allocation-vcores 1
yarn.scheduler.maximum-allocation-vcores 4 极限情况下,是只有【32/4】8个container容器
CDH官方经过大量验证,经验值,container容器最大分配vcore不要超过5
故一般我司生产上设置 yarn.scheduler.maximum-allocation-vcores 4
yarn.nodemanager.resource.memory-mb 96G
yarn.scheduler.minimum-allocation-mb 1G
yarn.scheduler.maximum-allocation-mb 12G 极限情况下,是只有8个container容器
也就是说:1个container 12G,4vcore ===》 1vcore 使用3G
扩展【JVM内存不要超过32G】
【内存指针压缩的技术 】
https://blog.csdn.net/weixin_44641024/article/details/103248842
调度器
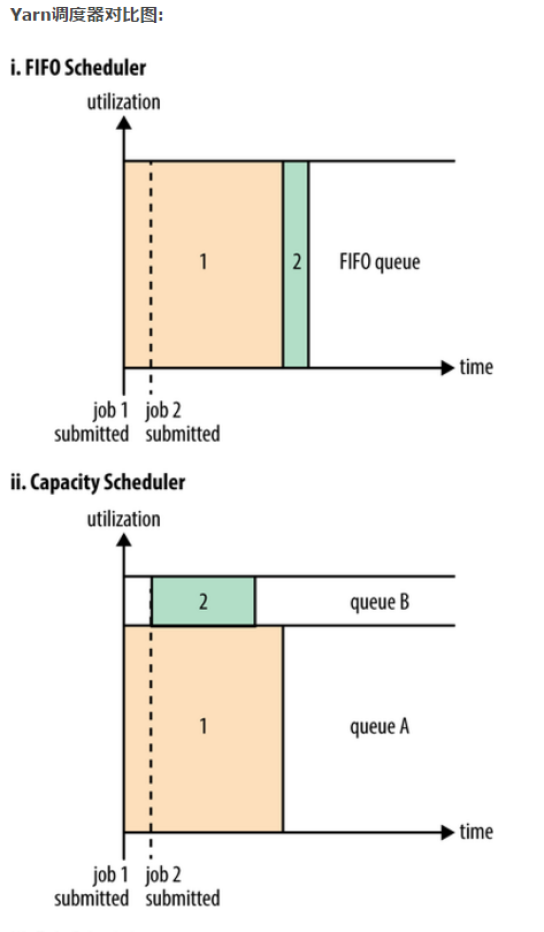
FIFO Scheduler
把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
在FIFO 调度器中,小任务会被大任务阻塞。
Capacity调度器
有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
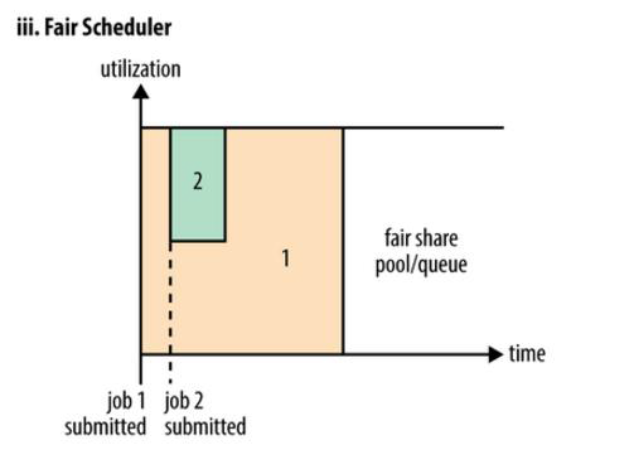
Fair调度器
我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
生产上 更多使用 公平调度器
在Fair调度器中,我们不需要预先占用一定的系统资源,
Fair调度器会为所有运行的job动态的调整系统资源。
当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;
当第二个小任务提交后,从提交到获得资源会有一定的延迟,
因为它需要等待第一个任务释放占用的Container。
小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。
最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。