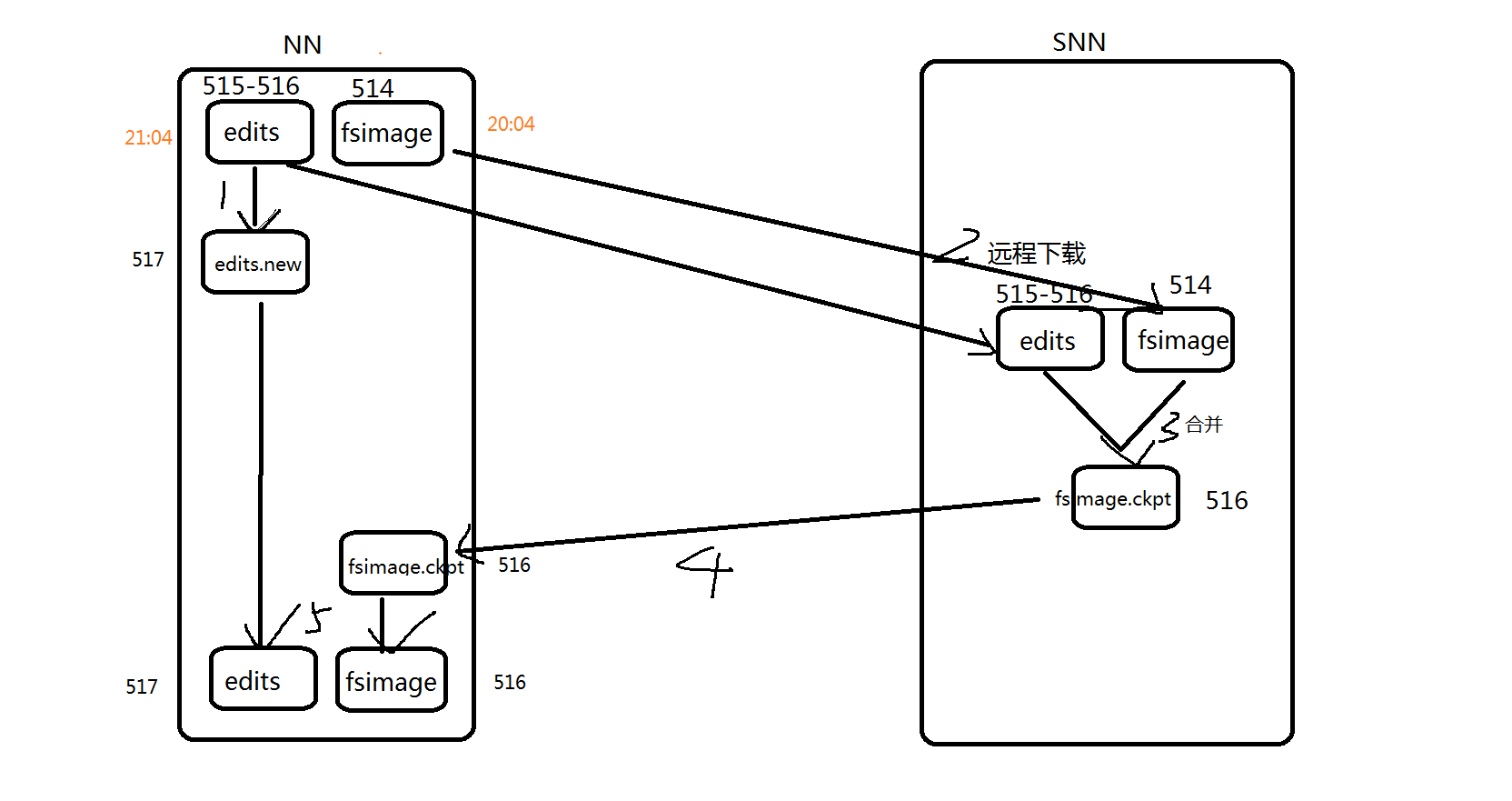
SNN操作流程 一般主要是面试,但是一定要了解 帮助对hdfs的底层实现基本掌握。
生产上我们是不用SNN,是用HDFS HA
NN active NN standby 热备
hadoop命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[bigdata@hadoop001 ~]$ hadoop Usage: hadoop [--config confdir] COMMAND where COMMAND is one of: fs run a generic filesystem user client version print the version jar <jar> run a jar file checknative [-a|-h] check native hadoop and compression libraries availability distcp <srcurl> <desturl> copy file or directories recursively archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive classpath prints the class path needed to get the credential interact with credential providers Hadoop jar and the required libraries daemonlog get/set the log level for each daemon s3guard manage data on S3 trace view and modify Hadoop tracing settings or CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
是否支持压缩
1 2 3 4 5 6 7 8 9
[bigdata@hadoop001 ~]$ hadoop checknative 20/11/30 22:06:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Native library checking: hadoop: false zlib: false snappy: false lz4: false bzip2: false openssl: false
[bigdata@hadoop001 ~]$ hdfs fsck / 20/11/30 22:14:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Connecting to namenode via http://hadoop001:50070/fsck?ugi=bigdata&path=%2F FSCK started by bigdata (auth:SIMPLE) from /172.22.212.16 for path / at Mon Nov 30 22:14:07 CST 2020 .........Status: HEALTHY Total size: 181851 B Total dirs: 14 Total files: 9 Total symlinks: 0 Total blocks (validated): 7 (avg. block size 25978 B) Minimally replicated blocks: 7 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 1 Average block replication: 1.0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Number of data-nodes: 1 Number of racks: 1 FSCK ended at Mon Nov 30 22:14:07 CST 2020 in 6 milliseconds
[bigdata@hadoop001 ~]$ hdfs dfsadmin -safemode get 20/11/30 22:17:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Safe mode is OFF
[bigdata@hadoop001 hadoop]$ hdfs dfs -put README.txt 【写】 20/11/30 22:19:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[bigdata@hadoop001 hadoop]$ hdfs dfsadmin -safemode enter 20/11/30 22:21:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Safe mode is ON [bigdata@hadoop001 hadoop]$ hdfs dfs -put NOTICE.txt 20/11/30 22:21:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable put: Cannot create file/user/bigdata/NOTICE.txt._COPYING_. Name node is in safe mode.
[bigdata@hadoop001 hadoop]$ hdfs dfs -rm /user/bigdata/input/1.log 20/11/30 22:30:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 20/11/30 22:30:07 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop001:9000/user/bigdata/input/1.log' to trash at: hdfs://hadoop001:9000/user/bigdata/.Trash/Current/user/bigdata/input/1.log
[bigdata@hadoop001 hadoop]$ start-balancer.sh starting balancer, logging to /home/bigdata/app/hadoop-2.6.0-cdh5.16.2/logs/hadoop-bigdata-balancer-hadoop001.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
DiskBalancer distributes data evenly between different disks on a datanode. DiskBalancer operates by generating a plan, that tells datanode how to move data between disks. Users can execute a plan by submitting it to the datanode. To get specific help on a particular command please run hdfs diskbalancer -help <command>. --help <arg> valid commands are plan | execute | query | cancel | report